클릭 >> Hello, world !! (from ShadowEgo)
2017년 9월부터 2018년 2월까지 인포리언스는 다양한 연구개발 프로젝트를 수행했습니다. 2건의 특허가 새로 등록되었고, 1건의 특허를 출원목록에 추가하였으며, 자연어 처리(Natural Language Processing) 기술을 응용한 프로젝트, 그리고 수치 시계열(Time Series) 분석 기술을 활용한 프로젝트를 수행하여 그 결과들을 외부기업들 및 연구기관에 공급하였습니다. 또한 CoDIP(http://222.114.71.21:10100/2017/07/31/codipintro1/)%EC%97%90 탑재할 시계열 패턴 학습 및 자동 패턴 탐지 기술을 계속 개발하고 있습니다.
(1) 새로운 특허의 등록과 출원
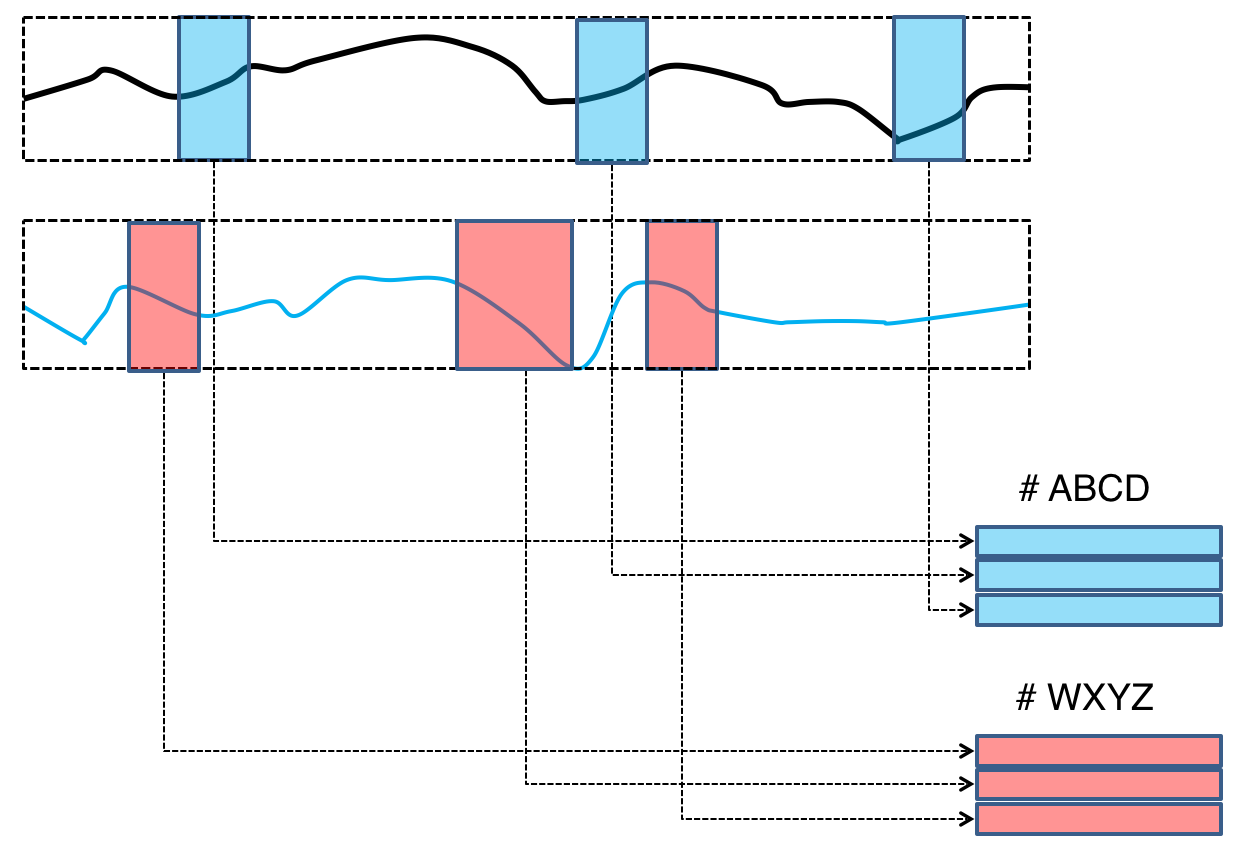
2017년 10월에는 2건의 특허가 새롭게 등록되었고, 2018년 1월에는 1건의 특허를 추가로 출원하였습니다. 2017년 10월에 등록된 2건의 특허는 지속적으로 생성되는 수치 시계열에서부터 주요한 패턴을 찾아내고 활용하는 기술을 담고 있습니다. 이 특허들은 여러 종류의 시계열 데이터가 동시에 입력될 때, 각 개별 시계열 데이터에서부터 중요한 특이 패턴들을 찾아내고, 각 패턴들 사이의 관련성과 의미를 자동적으로 찾아내는 과정에 필요한 원천적인 기술을 설명하고 있습니다. 2018년 1월에 새로 출원한 특허는 고차원 (multi-dimensional) 시계열 데이터에서 패턴을 찾아내는 과정에 사람의 지식과 머신러닝 알고리즘을 통합 적용하여 클라우드형 데이터 서비스를 지능화하는 기술에 관한 것입니다. (진정한 의미에서의 “information + experience = inforience” 라고 할 수 있습니다.)

그림 1. 시계열 데이터에서 패턴을 찾아내는 과정의 개념
인포리언스는 이미 등록(출원)된 국내 및 미국 특허들과 이번에 새로 등록(출원)된 특허들에 명시되어 있는 기술들을 바탕으로, 시계열 데이터의 특성과 활용방법을 자동적으로 찾아내는 지능적인 시스템을 개발하고 있습니다. 이 개발이 완료되면 사람의 동작이나 건강상태, 상황 정보, 특정 시스템이나 서비스의 상태, 그리고 여러가지 사회적 현상과 흐름 등을 스스로 탐지, 이해하는 지능적인 서비스를 구현할 수 있습니다. 이 기술들은 모두 CoDIP에 탑재될 예정입니다.
(2) SEED API 의 활용
SEED API는 영문 단어, 문장, 텍스트로부터 다양한 특성을 추출하는 기능을 포함하고 있으며, 이전 포스팅(http://222.114.71.21:10100/2017/08/11/seedapi1/)%EC%97%90%EC%84%9C 그 개념을 간단히 소개한 바 있습니다. SEED API는 외부 기업의 영어 학습용 온라인 서비스에 시범적으로 활용되고 있습니다. SEED API에 적용된 기술들은 지능적인 영문 텍스트의 분석을 필요로 하는 다른 서비스에도 활용될 수 있습니다. (예를 들어, 추후에 언급할 기술 흐름 분석 시스템에서도 관련 기술의 일부가 활용됩니다.)
인포리언스는 SEED API의 기능과 출력을 체험해 볼 수 있는 웹사이트를 가까운 시일 안에 오픈할 예정입니다.
(3) 뉴스 흐름 분석
인포리언스는 온라인 뉴스에 나타난 이슈의 흐름들을 분석하는 연구를 수행하였습니다. 특히 지난 2년(2016년 1월1일 ~ 2017년12월31일)동안 우리 사회에는 정치적, 사회적, 기술적인 변화와 울림이 참 많았는데, 온라인 뉴스에도 그와 같은 패턴이 고스란히 반영되었음을 확인할 수 있었습니다. 이 연구의 결과와 활용방안을 느껴볼 수 있는 새로운 포스팅과 웹사이트를 가까운 시일 안에 오픈할 예정입니다.

그림 2. 지난 2년간 특정 정치인의 이름이 온라인 뉴스에서 언급되는 패턴의 흐름 (누굴까요?)
(4) 기술 흐름 분석
기술 집약적 산업은 우리나라의 중요한 성장 동력들 중의 하나이기 때문에, 기술 변화의 현황과 흐름을 파악하고 예측하는 일은 매우 중요합니다. 따라서, 인포리언스는 다양한 관련 데이터를 통합 활용하여 국제적인 기술 변화의 흐름을 엄밀하게 파악할 수 있게 하는 서비스를 독자적으로 개발하고 있습니다.

그림 3. 2007년을 제외하고는 HMM(Hidden Markov Model)이 활용되는 추세에는 큰 변화가 보이지 않습니다. 이 그래프에 의하면 최근에 각광받고 있는 CNN(Convolutional Neural Networks)과 LSTM(Long Short-Term Memory)이 활용되는 추세가 급격하게 늘어난 것은 2014년부터입니다.
기술 정보는 정확도가 생명이므로, 인포리언스는 뉴스 흐름 분석 과정에 활용된 기술들보다 더 발전된 기술들을 이 프로젝트에 적용하고 있습니다. 또한 IT분야의 기술 흐름을 측정하는 것에서 시작하여 점차 다양한 분야로 분석 대상을 확대해 나갈 예정입니다. 이 연구의 결과와 활용방안을 느껴볼 수 있는 새로운 포스팅과 웹사이트를 가까운 시일 안에 오픈할 예정입니다.
(5) 센서에 지능을 부여하는 오픈 클라우드 시스템
인포리언스는 누구나 자신의 센서에 지능을 부여할 수 있게 하는 오픈 클라우드 시스템을 개발하였습니다. 이 시스템은 사용자로 하여금 클라우드에 공간을 만들어 자신의 센서가 전송하는 데이터를 모을 수 있게 합니다. 사이버 공간은 일정 수준 이상의 기본 지능을 갖추고 있어 데이터에서 특정 패턴이 탐지되면 관련 정보를 출력하거나 사용자의 스마트폰으로 전송합니다. 이 외에도, 사용자는 자신이 원하는 지능을 직접 디자인하여 적용할 수 있으며, 자신의 사이버 공간에 가족이나 동료, 친구를 초대하여 데이터와 서비스를 공유할 수 있습니다.

그림 4. 온습도 데이터 분석 서비스의 개념
이 시스템은 한 센서 유통 기업이 온습도 센서에 적용하여 사업화하고 있습니다. 인포리언스는 이 시스템의 지능 수준과 사용자 인터페이스를 지속적으로 발전시키고 있으며, 센서가 아닌 다른 타입의 데이터에도 응용할 수 있도록 확장하고 있습니다.
(6) 시계열 데이터에서 자동적으로 패턴을 탐지
기술 흐름, 센서 데이터 등은 데이터의 종류는 확연히 다르지만, 시계열(time series)로 표현될 수 있다는 공통점을 가지고 있습니다. 시계열 데이터를 관찰하면 시간에 따른 상태(상황)의 변화를 확인할 수 있지만, 사람이 계속 데이터를 들여다 볼 수는 없다는 한계가 있습니다. 따라서, 시계열에 포함된 유의미한 패턴을 자동으로 탐지하는 기술이 전 세계의 많은 개발자들에 의해 연구되어 왔습니다.

그림 5. 인포리언스가 개발한 Anomaly Detection 알고리즘이 (과거 데이터 패턴에 대한 학습과정 없이) 주파수가 높아진 구간을 실시간으로 탐지한 예. (참 쉬워 보이죠? 그러나 쉽지 않습니다.)
인포리언스도 이와 같은 기술의 연구개발에 동참하고 있습니다. 특히, 인포리언스가 독자적으로 개발한 anomaly detection 기법은 과거 데이터에 대한 학습과정이 없는 (머신러닝을 활용하지 않는) ‘가벼운’ 알고리즘임에도 불구하고 좋은 성능을 보입니다. 인포리언스는 이 알고리즘을 다양한 종류의 데이터와 패턴에 적용하면서 수정, 보완하고 있습니다. 또한 고차원 (multi-dimensional) 시계열 데이터를 위한 anomaly detection 알고리즘과, 데이터가 과거에 이미 보였던 패턴들을 학습하여 anomaly를 탐지하는 머신러닝 기반의 ‘무거운’ 알고리즘에 대한 기술도 보유하고 있습니다. 이러한 연구의 결과와 활용방안을 느껴볼 수 있는 새로운 포스팅을 가까운 시일 안에 업로드할 예정입니다.

그림 6. 과거 데이터를 열심히 공부한 후에 새로 입력되는 데이터에 포함된 패턴을 탐지한다면. (LSTM, CNN, HMM 등등…)
(7) 앞으로의 연구개발
인포리언스는 데이터에 나타난 흐름과 패턴을 자동으로 탐지하고, 학습하며, 그 의미를 스스로 학습하는 지능적인 방법들을 지속적으로 연구개발하고 있습니다. 비교적 간단한 heuristic을 적용한 방법에서부터 대용량의 데이터에 대한 학습을 필요로 하는 머신러닝에 이르기까지, 사용자가 자신의 경험과 지식을 직접 부여하여 개인화(personalization)할 수 있게 하는 방법에서부터 사람의 참여가 전혀 필요없는 100% 자동화된 기술에 이르기까지, 그리고 센서와 같이 빠르게 수집되는 데이터에서부터 문서 데이터와 같이 비교적 느리게 수집되지만 다양한 의미가 포함되어 있는 데이터까지, 연구개발의 스펙트럼을 계속 넓혀가고 있습니다.
[…] https://inforience.net/2021/01/28/bias-ai/ […]