클릭 >> Hello, world !! (from ShadowEgo)
1편에 이어서.
지난 포스트(http://222.114.71.21:10100/2019/05/07/machine_vibration/)에서는 CRNN(Convolutional-RNN)을 활용하여 기계 진동(소음)에 포함된 이상 패턴을 탐지하는 방법에 대해 간단하게 소개하였다. 이번 포스트에서는 좀 더 충분한 양의 데이터에 다른 종류의 학습 모델을 적용한 결과를 간략하게 확인해 보자.
데이터 설명
2016년도에 IEEE Transactions on Reliability에 발표된 논문[1]은 진동(소음) 데이터를 활용하여 air compressor의 상태를 모니터링하는 방법을 제시하고 있다. 이 논문에서는 한 종류의 healthy state (normal) 와 7 종류의 fault state (anomaly) 들에 해당하는 데이터를 대상으로 연구를 진행하였다. 각 state에는 225개의 데이터 파일들이 포함되어 있다.
가장 먼저, healthy state와 fault state에 해당하는 진동(소음) 데이터를 직접 들어보자. 해당 기계에 대한 도메인 지식이 없는 사람이 소리만으로 두 상태를 구분하는 것은 불가능할 듯 하다.
소리 1. Normal state data 소리 2. Fault state data문제 정의
논문[1]은 자신들이 제시한 데이터 preprocessing 과정 및 학습 모델을 활용하면 매우 높은 정확도로 각 state들을 구분할 수 있다고 언급하고 있다. 이 논문은 각 state를 탐지(구분)하는 문제를 classification의 관점에서 풀었는데, 모든 state들에 해당하는 데이터가 충분히 확보되어 있는 상황을 가정하고 있다. Support Vector Machine (SVM)을 학습 모델로 채택하였으며, SVM의 효율적인 학습과 활용을 위해 입력 데이터에 대한 preprocessing, feature extraction 및 feature selection 과정에 많은 양의 노력을 할애하고 있다. 그러나 실제 환경에서는 normal 상황에 비해 anomaly 상황이 자주 나타나지 않아 anomaly state에 대한 충분한 데이터를 수집하기 어렵다. 따라서 anomaly state 에 나타나는 특성을 학습할 충분한 기회를 학습 모델에게 부여할 수 없게 된다. 또한 어떠한 feature가 추출 가능하며, 추출 가능한 feature들의 활용성은 어느 정도나 되는지 예측(판단)하는 작업도 만만치 않다.
본 포스트에서는, 2가지 관점에서 논문[1]과는 다른 접근 방식을 채택해 보았다. 첫째, classification의 관점이 아닌, anomaly detection의 관점에서 문제를 해결해 보았고, 둘째, deep learning 모델을 활용하여, 데이터에 대한 preprocessing, feature extraction 및 feature selection 과정을 최소화하였다.
Generative model을 써서 anomaly detection 방식으로 풀어보자
일반적으로 anomaly detection 과정에서는 학습 모델로 하여금 normal 데이터의 특성을 학습하게 한 뒤에, normal state와 anomaly state가 섞여있는 데이터에서 anomaly state에 해당하는 데이터를 찾아내도록 한다. 실제 현장에서 anomaly state에 해당하는 데이터를 충분히 수집하기 어렵기 때문인데, 데이터를 수집할 목적으로 기계 장치에 실제로 문제를 일으키거나, 일부러 고장을 낼 수 없다는 점을 생각해 보면 쉽게 이해할 수 있다.
Normal state 의 특성에 대한 학습을 마친 후에는 새로 입력된 데이터가 normal state 와 얼마나 유사한가를 판단한다. 이 과정에서 generative model 의 reconstruction 기능을 활용하는데, generative 모델의 학습 과정이 충분히 이루어질 경우, 새로 입력된 데이터가 normal state 에 가까울 수록 reconstruction 결과가 원래의 데이터와 유사한 형태를 나타내게 된다는 점을 활용하는 것이다. 다시 말해서, 입력된 데이터의 reconstruction 결과가 많이 일그러지면, 그 데이터는 anomaly state 에 해당할 가능성이 높아지는 것이다.

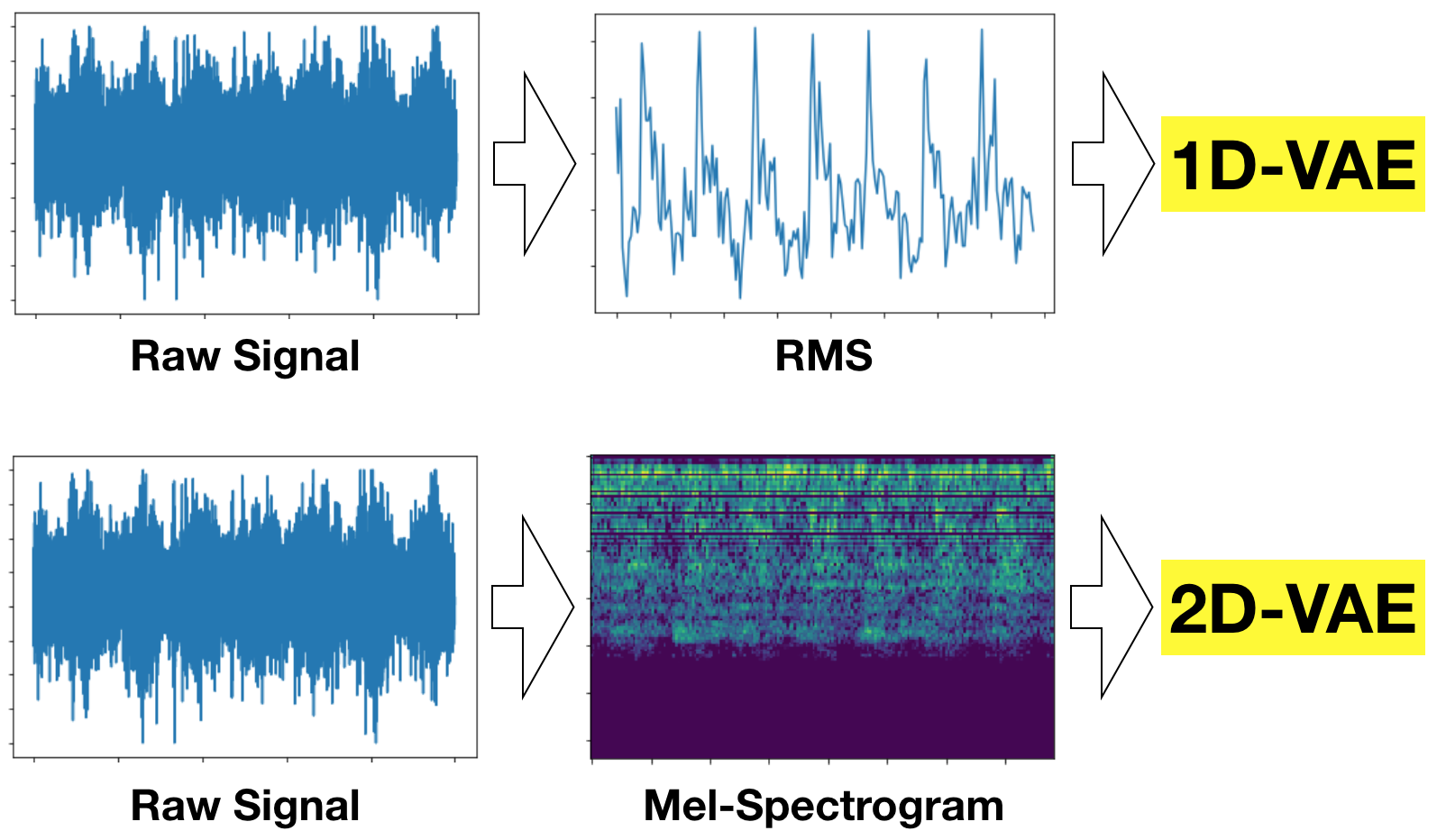
그림 1은 본 실험의 2가지 개념을 나타낸다. 진동이나 사운드 데이터에서는 다양한 feature 들을 추출할 수 있는데, 가장 많이 쓰이는 mel-spectrogram을 필두로 하여, 다양한 time-domain features, frequency domain features, time-frequency domain representations, phase-space dissimilarity measurements, complexity measurement 들을 활용할 수 있다. 인포리언스는 이러한 분류들에 해당하는 40여 가지의 다양한 feature 들을 활용하고 있으나, 이번 실험은 최대한 간단한 preprocessing 과정을 적용하는 것을 목표로 하므로, 사운드 파워의 특징을 나타내는 가장 기본적인 RMS[2]와 사운드 분석 과정에서 가장 널리 쓰이는 mel-spectrogram 을 활용한다.
이번 실험에서는 대표적인 generative model 중의 하나인 Variational Autoencoder (VAE)를 사용한다. [3, 4, 5] VAE는 raw 데이터에서 latent feature들을 추출하는 encoder 네트워크와 이를 다시 복원하는 역할을 하는 decoder 네트워크로 구성된다. 대표적인 generative model 중의 하나인 Generative Adversarial Network (GAN) [6]을 선택하는 것도 가능하겠지만, anomaly detection 응용에 GAN을 잘 활용하려면 추가적인 trick 이 요구되고 학습 안정성도 상대적으로 높지 않으므로, GAN을 활용한 실험 결과는 추후에 포스팅하기로 하고, 이번 실험에서는 활용하지 않는다. [7, 8]
RMS는 각 프레임에서 1차원의 정보만 추출하므로 1차원 시계열이 추출되며, mel-spectrogram은 mel 의 수에 해당하는 고차원의 정보를 추출하므로 (이번 실험에서는 mel의 수를 128로 지정) image 형태의 feature가 추출된다. 따라서, RMS를 추출할 경우에는 1-dimensional convolution layer로 구성된 VAE를 활용하고, mel-spectrogram을 추출할 경우에는 2-dimensional convolution layer로 구성된 VAE를 활용한다.
이번 포스트에서는 7가지 fault state들 중에서 flywheel[9]에 fault가 발생한 경우를 탐지하도록 했다. Normal state에 해당하는 225개의 데이터 중에서 112개를 무작위로 골라 학습 데이터로 활용하였고, 나머지 113개는 테스트 데이터로 활용하였다. Flywheel fault state의 데이터들 중에서 113개를 무작위로 골라 테스트 데이터로 활용하였다. Anomaly detection 방식의 실험이므로, fault data는 학습 데이터에 포함시키지 않는다.
실험 결과

그림 2는 1D-VAE를 활용했을 때의 실험결과를 나타낸다. 그림 2의 상단의 그래프는 1D-VAE가 normal 데이터 및 anomaly 데이터에 대해 출력한 reconstruction error 값의 분포를 나타낸다. 전체적으로 anomaly 데이터에 대한 loss 값이 높게 분포되고 있으며, normal 데이터와 anomaly 데이터의 loss값의 분포가 잘 분리되는 형태를 보인다. 그림 2의 하단의 내용은 loss 값의 기준을 0.0026으로 잡았을 때의 anomaly 탐지 결과의 정확도를 나타낸다. Normal 데이터에 대해서는 113개의 데이터 중에서 3개를 잘못 분류하였고, anomaly 데이터에 대해서는 113개의 데이터 중에서 4개를 잘못 분류하여, ROC_AUC 값이 97%에 육박하였고, Kappa_Score는 94% 정도를 나타내었다.

그림 3은 2D-VAE를 활용했을 때의 실험결과를 나타낸다. 그림 3의 상단의 그래프는 2D-VAE가 normal 데이터 및 anomaly 데이터에 대해 출력한 reconstruction error 값의 분포를 나타낸다. 1D-VAE를 적용했을 때와 마찬가지로, anomaly 데이터에 대한 loss 값이 높게 분포되고 있으며, normal 데이터와 anomaly 데이터의 loss값의 분포가 잘 분리되는 형태를 보인다. 그림 3의 하단의 내용은 loss 값의 기준을 0.116으로 잡았을 때의 anomaly 탐지 결과의 정확도를 나타낸다. Normal 데이터에 대해서는 113개의 데이터 중에서 2개의 데이터를 잘못 분류하였고, anomaly 데이터에 대해서는 113개의 데이터 중에서 3개를 잘못 분류하여, ROC_AUC 값이 98%에 육박하였고, Kappa_Score는 95% 정도를 나타내었다.
전체적으로, 1D-VAE와 2D-VAE가 모두 준수한 성능을 보여주었는데, 위의 결과만 놓고 보자면 2D-VAE가 아주 미세하게 더 나은 결과를 보여주었다. 그러나, 학습 및 테스트 과정에서 1D-VAE가 훨씬 가볍고 빠르게 동작한다는 사실도 기억할 필요가 있다. (2D-VAE 의 내부 파라메터의 수가 훨씬 많기 때문에 당연한 현상이다.) 비슷한 성능을 보인다면, 실제 응용 현장에서는 더 빨리 학습시킬 수 있고 더 빨리 결과를 출력할 수 있는 모델을 선호할 수도 있기 때문이다.
Future works
위에서 잠깐 언급하였지만, 진동이나 사운드 데이터에서 추출 가능한 1D feature 들은 인포리언스가 활용하고 있는 것들만 40여 종류에 이를 정도로 무척 다양하다. 이번 실험에서는 RMS가 충분한 역할을 했지만, 다른 동작 패턴을 보이는 기계 장치의 진동(소음) 데이터에 대해서도 그러하다는 보장은 없으므로, 다른 feature들을 활용한 실험을 해보는 것도 좋을 것이다. 그리고 진동(소음) 데이터를 수집하는 과정에서 환경 소음이 포함된다면, 이번 실험에서 적용한 데이터 활용방법이나 학습 모델로는 좋은 결과를 얻기 어려울 것이다.
인포리언스는 진동(소음) 데이터에서 anomaly 를 탐지하는 것과 관련된 다양한 연구를 계속 진행하고 있으며, 관련된 주요 연구문제를 해결해 가고 있다.
References
- Nishchal K. Verma, R. K. Sevakula, S. Dixit and A. Salour, Intelligent Condition Based Monitoring using Acoustic Signals for Air Compressors, IEEE Transactions on Reliability, vol. 65, no. 1, pp. 291-309, 2016.
- https://www.audiorecording.me/understanding-what-does-rms-stands-for-in-audio-definition-details.html
- https://arxiv.org/abs/1312.6114
- https://arxiv.org/abs/1606.05908
- https://towardsdatascience.com/intuitively-understanding-variational-autoencoders-1bfe67eb5daf
- https://arxiv.org/abs/1703.05921
- https://blog.lunit.io/2017/06/13/ipmi-2017-unsupervised-anomaly-detection-with-gans-to-guide-marker-discovery/
- https://medium.com/vitalify-asia/gan-for-unsupervised-anomaly-detection-on-x-ray-images-6b9f678ca57d
- https://en.wikipedia.org/wiki/Flywheel
[…] https://inforience.net/2021/01/28/bias-ai/ […]