클릭 >> Hello, world !! (from ShadowEgo)
들어가며.
최근 몇 년간 딥러닝 기술의 발전과 함께 Machine Intelligence 가 비약적으로 향상되어 왔고 아직까지 그 성장세가 여전하다. 초기 딥러닝 모델은 많은 연산량을 필요로 했기에 서버나 PC의 GPU 에서만 주로 동작했으나, 모바일 프로세서의 발전과 모델의 경량화, 그리고 모바일 환경에 최적화된 라이브러리의 등장에 힘입어 이제는 모바일폰에서도 딥러닝 모델을 사용하는 것이 가능해졌다. 장면(scene) 인식, 얼굴 인식, 영상 화질의 개선, 음성 인식과 같은 많은 응용들에서 필요로 하는 인식 과정이 서버가 아닌 작은 용량의 모바일폰 안에서 수행되는 것이다.
물론, 영상/음성 데이터를 서버로 전송하고, 서버에서 처리한 결과를 다시 전송받는 형태의 Cloud 기반 인식도 가능하지만, 반응속도가 중요한 서비스에서는 모바일폰에서의 인식이 필수적이다.
그렇다면, 과연 모바일폰에서 동작하는 딥러닝 모듈의 속도는 어느 정도나 될까? 데스크탑 상에서 GPU 를 활용하는 경우에 비해서 얼마나 느릴까? 이러한 의문들을 해결해주는 고마운 사이트가 바로 AI-Benchmark 이다 [1], [2]. AI-Benchmark 에서는 MobileNet, ResNet, InceptionNet 등과 같은 대표적인 딥러닝 모델들이 여러 타입의 모바일폰에서 실제로 어느 정도의 속도로 동작하는지 측정한 결과를 소개하고 있다.

벤치마크에는 어떠한 앱과 뉴럴 네트워크 모델이 포함되어 있는가?
벤치마크가 체감 성능을 잘 반영하기 위해서는 실제로 많이 활용되는 뉴럴 네트워크 모델들을 사용해야 한다. AI-Benchmark 에 포함된 문제는 물체 인식, 얼굴 인식, 문자 인식 등 9개 이고, 각 문제에 대해 대표적인 뉴럴 네트워크 모델 1-2개를 사용하였다. (http://ai-benchmark.com/tests.html 참조) 각 문제와 문제에 사용된 뉴럴 네트워크 모델은 아래와 같다.
- 물체 인식 / MobileNet V2
- 물체 인식 / Inception V3
- 얼굴 인식 / MobileNet V3
- 여러 물체 동시 인식 / MobileNet V2
- 문자 인식 / CRNN / Bi-LSTM
- Deblurring / PyNET
- Super Resolution / VGG-19
- Super Resolution / SRGAN
- 보케 시뮬레이션 / U-Net
- Semantic Segmentation / DeepLab-V3+
- Photo Enhancement / DPED-ResNet
- Text Completion / LSTM
Text completion 을 제외하면 모두 영상 처리에 관련된 문제인 것이 다소 아쉬운 부분인데, 특히 모바일폰에서 많이 사용되는 음성 인식, 번역 응용 등이 포함되지 않은 것이 아쉽다.
어떠한 환경에서 측정하는가?
우선 AI 벤치마크는 텐서플로우를 사용한다. 텐서플로우가 모바일 장치에 대해 가장 많은 지원을 하고 있다는 점을 고려하면 당연한 선택으로 보인다. PyTorch 진영에서도 모바일 지원을 시작했지만 아직 텐서플로우와의 격차가 크다.
안드로이드에서 테스트 되었으며, CPU Float, CPU Integer, NNAPI Float, NNAPI Integer 구성을 포함한다. CPU vs NNAPI (GPU 또는 NPU 사용), Float vs Quantized Integer 간에는 각기 장단점이 있으므로 각 환경에서 따로 평가할 필요가 있다. 예를 들어, Float 모델의 경우, 데스크탑 환경에서 사용하는 Float 모델을 그대로 사용할 수 있고 그 정확도가 높다는 장점이 있다. Integer 모델의 경우, 더 빠르게 동작하고 Memory 를 적게 사용한다는 장점이 있다. 또한, 최신 모바일폰에는 GPU 또는 NPU 의 가속기가 탑재되어 있지만, 가속기가 없는 환경에서는 CPU 에서 딥러닝 모델을 사용하는 경우도 있다.
모바일폰에서의 처리 속도는 PC GPU 에 비해 얼마나 느린가?

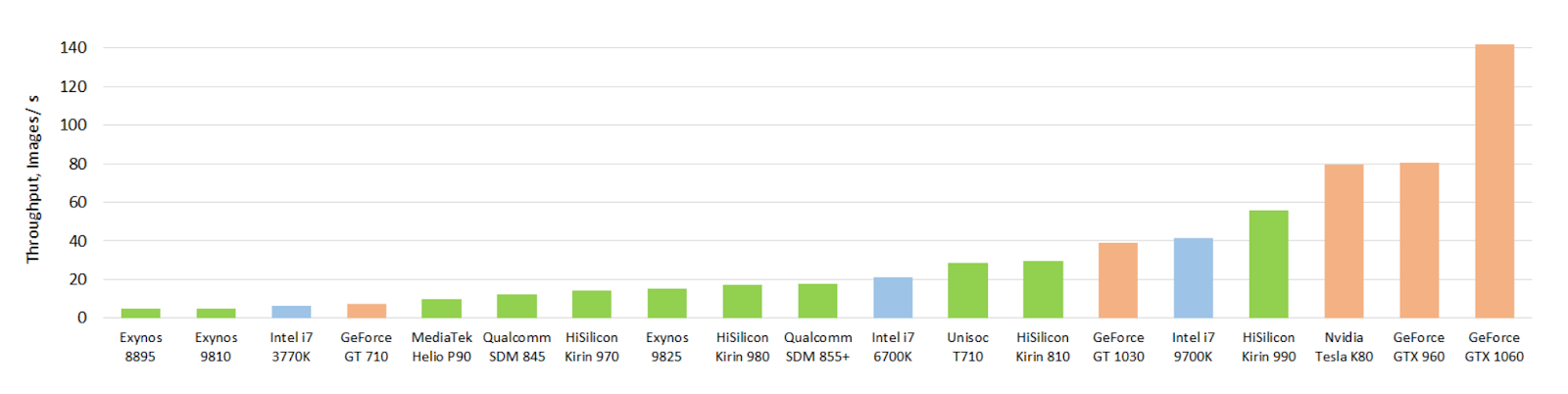
AI-Benchmark 논문에서 비교한 초당 처리할 수 있는 이미지수는 그림 2와 같다 (InceptionNet-V3 구조 사용). 모바일폰 SOC 중 가장 좋은 성능을 내는 HiSilicon Kirin 990 의 경우, 1초에 약 55 장의 이미지를 처리할 수 있어 GTX 1060 (초당 140 이미지 처리) 대비 40% 정도의 성능을 보였다. 이것은 모바일 장치에서도 실시간 처리에 문제가 없다고 판단할 수 있는 수준이며, PC GPU 와 모바일 SOC 의 크기, 전력 소모량, 가격을 고려하면 모바일 SOC 가 더 효율적이라고 볼 수 있다.
단, 이 비교에서는 batch size, half/full precision 등에서 차이가 있었음을 감안해야 한다.
모바일폰 성능의 발전
또 하나 주목해야 할 점은 모바일폰 SOC 성능의 발전속도이다. 2017년 모델인 Galaxy S8 (Exynos 8895) 에서의 InceptionNet 인식 속도는 121 ms 이었는데, 2020년 모델인 Galaxy S20 (Exynos 990) 에서는 58 ms 이다. 3년만에 처리 속도가 2배로 늘었다. 딥러닝 모델에 특화된 NPU (Neural Processing Unit) 를 탑재한 HiSilicon Kirin 990 에서는 처리속도가 무려 13 ms 으로 더 줄어든다.
마무리
모바일폰에서 딥러닝 모델을 사용하고자 하는 개발자, 연구자라면 꼭 한번 벤치마크 결과를 확인해 보길 추천한다. CPU/GPU, Float/Integer 모델 선택, 최소 지원 모바일폰 사양을 결정하는데 큰 도움이 될 것이다.
References
- [1] http://ai-benchmark.com/
- [2] Ignatov, Andrey, Radu Timofte, Andrei Kulik, Seungsoo Yang, Ke Wang, Felix Baum, Max Wu, Lirong Xu, and Luc Van Gool. “Ai benchmark: All about deep learning on smartphones in 2019.” In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pp. 3617-3635. IEEE, 2019.
[…] https://inforience.net/2021/01/28/bias-ai/ […]