클릭 >> Hello, world !! (from ShadowEgo)
동적 데이터 패턴의 예와 중요성
바야흐로 데이터 활용의 시대다. 활용할 수 있게 된 데이터의 종류와 양이 폭증했을 뿐 아니라, 데이터를 생산하는 주체도 다양해졌으며, 이에 따라 데이터를 저장하고 분석하는 기술도 발전하고 있다. 또한 소수의 전문가들에 의해서만 데이터가 분석되었던 시대를 지나, 이제는 누구나 직접 데이터를 수집, 분석, 활용할 수 있는 시대로 나아가고 있다. 활용 대상이 될 수 있는 데이터의 종류와 양은, 한 명의 사용자가 착용한 웨어러블 장치가 수집하는 소량의 센서 데이터에서부터, 수백만명의 사용자들이 활동하는 온라인 사이트에 쌓인 엄청난 양의 컨텐츠와 로그 데이터에 이르기까지, 우리가 상상할 수 있는 것 이상이다.
데이터는 지속적으로 수집된다. 따라서, 시간에 따라 어떻게 변화했는가를 파악하는 것이 매우 중요하다. 환율이나 주식 관련 데이터들은 날마다 계속적으로 쌓이고 있으며, 개인의 카드 사용 내역도 계속해서 차곡차곡 기록된다. 일반적으로 우리는 일정한 기간 동안 쌓인 데이터에 나타난 통계적인 수치를 파악하는 것에 관심이 많지만, 그에 못지 않게 그 데이터가 시간에 따라 어떠한 변화 패턴을 보였는지, 그 변화 패턴은 무엇에 의해 비롯되었는지 등을 알고 싶어한다. 특히 모바일 헬스케어, 사물 인터넷, 핀테크 등과 같은 새로운 기술 트렌드의 등장에 의해 수집될 수 있게 된 환경, 행동, 생체, 소셜 미디어, 금융 거래 데이터 등과 같이 지속적으로 생산, 유입되는 데이터들에 포함된 동적인 특성 – 예) 시간에 따른 데이터의 추세변화 또는 여러 데이터간 상관 관계의 변화 등 – 을 신속하게 발굴하고 활용해야 할 필요성이 커지고 있다.

그림 #1. 데이터는 살아 움직인다.
위의 그림은 우리가 쉽게 접할 수 있는 데이터들의 그래프이다. 우리는 주식시장의 주요 수치 데이터가 어떻게 변화하는지, 우리가 살고 있는 곳의 날씨는 과거에 비해 얼마나 빨리 더워지고 있는지, 나의 몸에 부착한 웨어러블 센서의 데이터는 어떠한 패턴을 그리는지, 뉴스 포털에 올라오는 기사의 이슈들은 시간에 따라 어떻게 바뀌는지 등을 궁금해 한다. 더 나아가, 데이터로부터 뚜렷한 변화 패턴을 관찰하게 되면, 그러한 패턴을 발생시킨 원인을 찾고 싶어한다.
하나의 데이터에는 다양한 형태의 변화 패턴이 포함될 수 있다. 수치가 갑자기 상승하거나 하강할 수 있으며, 일정 기간동안 변화없이 특정 값을 유지할 수도 있다. 눈에 띄는 패턴이 주기적으로 발생할 수도 있으며, 여러 개의 패턴들이 복합적으로 나열되는 형태를 보일 수도 있다. 서로 다른 두 데이터가 높은 상관관계(Correlation)를 나타낼 수 있으며, 두 데이터 사이에 높은 인과관계(Causality)가 존재할 수도 있다. 따라서, 데이터에 포함된 다양한 동적 패턴들을 탐색, 발굴하고, 해당 패턴들의 원인을 고민하거나 패턴의 의미를 추출하여 적절히 활용하는 것은, 데이터 분석에 있어 가장 기본적이면서도 중요한 작업이다.
데이터 패턴의 탐색, 해석과 협업의 필요성

그림 #2. 공간에 배치한 센서의 위치가 바뀌기만 해도 데이터 패턴은 완전히 달라지게 되어, 새롭게 다시 관찰, 분석해야 한다.
데이터는 데이터를 생성해내는 주체의 특성과 상태를 표현한다. 데이터에 포함된 패턴은 때로는 매우 무질서해 보일 수 있으며, 그 존재 여부를 미리 예측하기가 어렵다. 데이터의 특성과 상태는 해당 주체의 내재적 특성에 의해 변화할 뿐만 아니라, 외부 요소의 영향에 의해서도 변화할 수 있다. 또한 변화를 일으키는 원인이 무엇인가에 따라 다양한 패턴을 보일 수 있다. 따라서, 데이터를 생산하는 주체에 대한 지식과 경험을 바탕으로 데이터에 포함되어 있을 법한 패턴에 대한 가설을 세우고, 해당 패턴의 존재 여부를 검증해야 한다.
데이터에 포함된 패턴을 탐색하는 방법에는 여러가지가 있을 수 있다. 가장 대표적인 방법은, 데이터마이닝 또는 머신러닝 등과 같은 분야에서 개발되어 온 알고리즘들을 적용하는 것이다. 이와 같은 방법을 적용할 때에는, 알고리즘을 적용하는데 필요한 다양한 파라메터들을 사용자가 직접 결정해야 할 수도 있으며, 이렇게 결정된 파라메터들의 내용에 따라 알고리즘의 동작 방식이나 탐색 가능한 결과들이 달라지게 된다. 또 다른 방법은, 데이터에 포함되어 있을 법한 패턴에 대한 표현(metric, indicator, 또는 query 등)을 사용자가 직접 만들어 낸 후, 해당 패턴이 실제로 데이터에 포함되어 있는지 검증하는 방법이다. 전자의 방법은 데이터마이닝 또는 기계학습 알고리즘과 파라메터에 대한 지식을 필요로 한다는 특성이 있는데 반해, 후자의 방법은 일반적인 사용자들도 자신의 경험과 지식을 기반으로 탐색 작업에 직접 참여할 수 있다는 장점이 있다.
데이터 패턴 탐색에 활용할 좋은 표현(metric, indicator, 또는 query 등)을 디자인하는 것은 매우 중요한 일이다. 또한 그러한 표현들을 누구나 쉽게 디자인하고 활용할 수 있게 하는 것도 그렇다. 세이버매트릭스(http://sabr.org/sabermetrics)는 야구 데이터에서 주요한 정보를 추출하기 위하여 다양한 지표를 디자인하고 활용하는 분야인데, 널리 활용되고 있는 중요한 지표들 중에는 전문가가 아닌, 그저 야구를 좋아하는 팬들에 의해 만들어진 것들도 많다. 결과적으로, 좋은 표현을 누구나 쉽게 만들 수 있게 되면, 다양하고 풍부한 지표가 만들어지고 활용될 수 있게 되어, 데이터의 가치가 크게 올라갈 수 있다.
데이터마이닝, 기계학습 또는 사용자에 의해 만들어진 표현 등에 의해 탐색된 패턴은 데이터를 활용하는 과정에서 매우 중요한 역할을 한다. 그러나 패턴 자체만으로는 활용성이 높지 않으며, 데이터가 나타낸 패턴에 대한 해석이 중요하다. 아무리 통계적으로 유의미한 (statistically significant) 패턴이라고 하더라도, 그 패턴이 무엇을 의미하는가를 이해하지 못하면 데이터 분석의 의미가 없어지게 된다.
데이터가 나타낸 패턴을 해석하고 의미를 부여하는 작업은 (적어도 현재까지는) 자동적으로 이루어질 수 없으므로, 데이터 분석자의 경험과 지식을 직접 반영할 수 있도록 해야 한다. 따라서, 이와 같은 작업을 적절히 수행할 수 있도록 하는 사용자 인터페이스를 제공하는 것도 역시 중요하다. 더 나아가, 분석자의 경험과 지식은 주관적이고 편향적일 수 있으므로, 다양한 시각으로부터 해석을 수집하여 활용할 수 있도록 협업 환경을 제공할 필요도 있다.
CoDIP

그림 #3. CoDIP 을 어떤 일에 써야 좋을까?
인포리언스는 다음과 같은 특성들을 모두 만족시키는 데이터 마이닝 플랫폼 (CoDIP) 을 개발하였고, 지속적으로 각 세부 기능을 발전시키고 있다.
- 수치 시계열 데이터에 포함된 동적 패턴을 쉽게 탐색할 수 있는 데이터 마이닝 플랫폼
- 전문적 알고리즘을 활용할 수 있을 뿐만 아니라, 데이터 내용에 대한 사용자의 경험적 지식을 query 에 반영하여 분석 작업에 활용할 수 있게 하는 데이터 마이닝 플랫폼
- 탐색된 패턴에 대한 해석을 저장, 활용할 수 있는 플랫폼
- 패턴의 탐색과 해석 작업을 여러 사용자와 함께 수행할 수 있는 협업형 플랫폼
- 저장된 패턴에 대한 실시간 탐지 기능을 활용할 수 있는 플랫폼
CoDIP 의 활용 과정은 다음과 같이 요약할 수 있다.
- 데이터 연결 : API 를 통해 CoDIP 에 데이터를 업로드한다.
- 데이터 확인 및 핸들링: CoDIP 이 제공하는 인터페이스를 통해 자신의 데이터를 확인하고 play 해본다.
- 원하는 패턴의 탐색: 자신이 원하는 패턴을 query 형태로 입력하여 해당 패턴의 존재와 통계적 특성을 알아낸다.
- 패턴의 해석과 기록: 발견된 패턴에 대한 주관적인 해석을 기록, 저장한다.
- 전문적인 분석 알고리즘의 활용: 머신러닝 및 데이터 마이닝 알고리즘을 데이터에 적용해 본다.
- 분석 결과의 공유: 자신의 분석 결과를 타 사용자 또는 전문가와 공유하거나, 다른 사용자의 분석 과정에 참여한다.
- 최종 결과의 활용: 분석 결과로 생성된 패턴 템플릿이나 머신러닝 모델을 실제적인 서비스에 적용한다.
CoDIP은 다음과 같은 독창적인 특성을 가지게 된다. (전 세계적으로, 다음과 같은 특성을 모두 만족시키는 소프트웨어나 서비스는 아직 출시된 바 없다)
- 일부 전문가에 의해서만 수행되어 온 데이터 마이닝 작업을 일반 사용자들도 일정 수준까지 직접 수행할 수 있도록 하여 자신들의 데이터에 어떠한 패턴이 포함되어 있을지 미리 스스로 탐색해볼 수 있게 한다.
- 전문적인 데이터 마이닝 알고리즘 뿐만 아니라 사용자가 자신의 데이터에 대해 알고 있는 경험적 지식을 분석 과정에 반영할 수 있게 한다.
- 경험적 지식의 예
- 주변 온도가 28도 이상이고, 소음이 레벨 4 이상인 상태가 30분 이상 지속되면 기계의 동작을 멈추고 상태를 점검해야 한다.
- 환율이 상승하고, 재고가 40% 이상이고, 지난 한 달간 비용이 30% 상승하면 관심 상태로 상황을 주시해야 한다.
- 가속도 센서의 변동 값이 없는 상태에서 심장 박동이 30% 이상 급상승하는 경우가 1주일에 3번 이상 발견될 경우 의사의 진찰을 받아야 한다.
- 경험적 지식의 예
- 데이터 분석 인프라나 서비스를 본격적으로 도입하기 전에 데이터에 대한 초기 단계의 분석을 사전에 수행하여 데이터 분석의 효과 및 데이터 분석에 필요한 예산 규모나 투자 규모를 미리 평가해볼 수 있다.
- 자신의 개인 데이터 분석을 직접 수행해 보고 그 결과를 활용할 수 있으며, 이 과정에서 데이터 분석에 대한 지식과 경험을 쌓을 수 있다.
- 정적인 데이터 분석 뿐만 아니라 시계열과 같은 동적 데이터 패턴에 대한 분석이 가능하다.
- 동일한 데이터에 대해 여러 사용자가 함께 분석 및 해석 과정에 참여할 수 있으므로, 협업을 통해 객관적이고 신뢰성 있는 결과를 도출할 수 있다.
- 데이터 분석 기술을 보유한 Mining expert 들과, 분석 기술은 보유하고 있지 않으나 데이터에 대한 경험적 지식을 가진 Domain expert 들의 효율적인 협업이 필요한 데이터 마이닝 과정에서, CoDIP 은 Mining expert 의 역할을 수행한다. 이를 통해, Mining expert 들이 없는 상황에서도 Domain expert 들이 최대한으로 자신만의 분석 및 해석 결과를 얻을 수 있도록 한다.

그림 #4. CoDIP 의 다양한 활용 모드
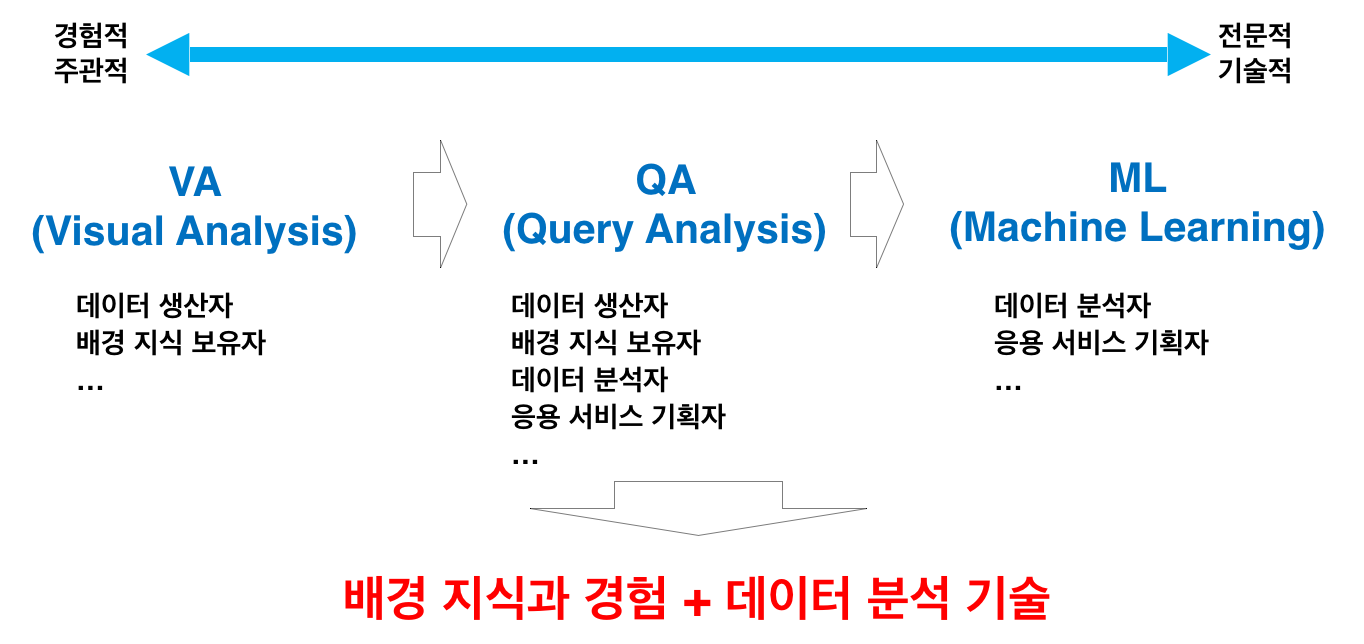
CoDIP 은 다양한 사람들이 자신의 지식 수준과 활용 목적에 맞게 선택적으로 활용할 수 있도록 다양한 활용 모드 – Visual Analysis, Query Analysis, Machine Learning, 자동 패턴 탐지 – 를 제공한다. Visual Analysis 는 누구나 직접 데이터를 확인하면서 유의미한 특성이 나타나는 곳에 해당 특성에 대한 자신의 생각과 의견을 적어넣고 다른 사용자들과 공유할 수 있게 하는 모드이다. Query Analysis 는 사용자가 직접 자신이 탐색하고자 하는 데이터 패턴을 query 형태로 만들어 입력하여 해당 패턴을 탐색하고 해석과 의견을 입력하는 모드이며, Machine Learning 모드는 데이터의 특성을 학습한 Machine Learning 모델을 학습시키고 활용하는 모드이다. 이와 더불어, 자동 패턴 탐지 모드는 새롭게 입력되는 데이터에서 유의미해 보이는 패턴의 후보들을 자동적으로 찾아내어 분석자 또는 응용 서비스에게 제공하는 작업을 수행한다.
각 모드의 개념과 자세한 활용 과정은 (2)편에서부터 소개하도록 한다.
핑백: 인포리언스 소식 (2017년 9월 ~ 2018년 2월) – Inforience