클릭 >> Hello, world !! (from ShadowEgo)
온라인에서 활동하시는 치밀한 선생님
윤러닝씨는 몇달 전부터 경제학을 공부하고 싶다는 생각을 해왔다. 그래서 정보를 좀 검색해 보니, 요즘에는 온라인으로 수강할 수 있는 강좌들도 많고, 학점도 딸 수 있다고 해서, 모 온라인 대학의 경제학 기초 과목을 수강하기로 했다. 나름대로 크게 마음을 먹고 행동으로 옮겼는데, 공부해야 할 양이 많고 시간도 많이 들 것 같아 슬쩍 걱정이 되었다. 그런데, 공부를 하다보니, 내가 얼마나 공부를 했는지, 어느 정도나 이해했는지, 어떤 내용을 좀 더 보충하면 좋을 지, 다음 단계에서는 어떤 자료를 보면 좋을 지 등과 같은 정보를 적절한 타이밍에 자동으로 알려주어서 생각보다 힘들게 느껴지지 않았다. 윤러닝씨는 그렇게 온라인 강좌 시스템의 안내에 따라 차근차근 기초 과목의 공부를 끝냈다. 만족스러운 결과를 얻어 공부가 재미있어진 윤러닝씨는 내친 김에 좀 더 높은 수준의 경제학 전공과목도 공부해 볼까 생각하며 즐거운 고민을 하고 있다.
위의 이야기는 가상의 시나리오지만, 최근의 교육환경은 위와 같은 시나리오가 실제로 가능해지게끔 계속해서 진화, 발전하고 있다. 다시 말해서, 누구나 원하는 주제의 강좌를 찾아 온라인으로 스스로 공부할 수 있고, 공부하는 동안 학습자의 학습 패턴과 수준을 측정, 분석해서 적절히 활용할 수 있게 된 것이다. 이러한 것들이 가능해진 것은, 학습 대상이 되는 많은 컨텐츠들이 디지털화되어 서비스로 제공되고 있고, 학습자 개인에 대한 다양한 데이터를 수집할 수 있게 되었으며, 이를 분석하고 활용할 수 있는 다양한 기술들이 뒷받침되고 있어서다.

그림 #1. Learning Analytics 에서의 데이터의 수집 저장, 선택, 분석, 해석, 활용까지. (Figure from “Learning Analytics: Concepts, methods, tools, achievements, research directions and perspectives, Learning Technology and Educational Engineering Lab”, Αngelique Dimitracopoulou)
인포리언스, SEED API
인포리언스는 데이터 분석, 머신러닝, Natural Language Processing (NLP) 등과 같은 분야의 기술들을 연구개발하는데, 최근에는 이러한 기술들을 학습자 친화적인 교육 서비스를 구축하는 것에 접목하기 위한 프로젝트를 진행하고 있다. 그 첫번째 테마로서, 영문 텍스트 분석 기술을 영어 학습 과정에 활용하는 것에 초점을 맞추고 있다. 인포리언스가 다른 기술들 중에서도 영문 텍스트 분석 기술을 활용하는 것을 첫번째 테마로 선택한 이유는 다음과 같다.
- 영문 텍스트 분석 기술은 오랜 기간에 걸쳐 전 세계적으로 (인포리언스 뿐만 아니라 많은 연구자들에 의해) 많은 연구가 이미 진행되어, 활용 가능한 결과들이 풍부한 편이다.
- 교육 환경에 기술적 요소들을 적절하게 접목시키기 위해서는, 해당 기술들에 대한 지식 뿐만 아니라 교육 및 학습 과정, 교육 서비스의 구조 및 학습자에 대한 이해와 경험을 갖추는 것이 필요한데, 영어는 많은 사람들이 다양한 목적으로 공부하는 주제이며 다양한 형태의 온라인 학습 서비스가 제공되고 있기 때문에, 이러한 이해와 경험을 수집하기에 적합하다.
SEED는 인포리언스에서 개발하고 있는 영문 텍스트 분석용 기본 API 의 명칭으로서, “Smart, English, Education, Data”의 약자이다. SEED API는 영문 컨텐츠들의 특성을 추출하는데 필요한 여러가지 기능들을 제공하는데, 학습자가 공부하고 있거나 지금까지 공부해 온 내용들로부터 학습자의 학습패턴, 수준, 학습방향 등을 파악하는 것에 활용할 수 있다. 더 나아가, 이렇게 파악된 결과를 바탕으로 새롭게 학습할 컨텐츠를 추천해 주는 데에도 활용할 수 있다.
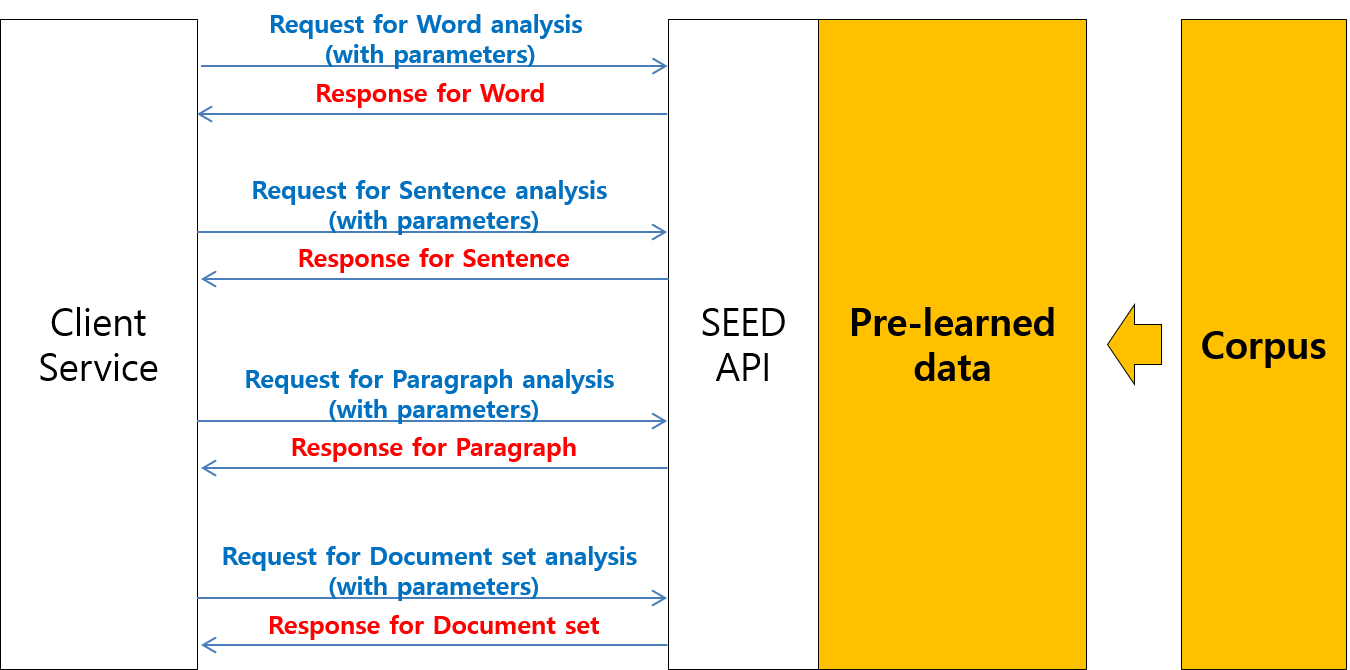
영어 학습 서비스를 제공하는 클라이언트 서비스들은 원하는 타이밍에 SEED API의 특정 기능을 호출하여 사용할 수 있다. SEED API 는 어떤 타입의 영어 학습을 목표로 하는가에 무관하게 모두 활용할 수 있도록 가장 일반적이면서도 중요한 기능들을 포함하고 있다. 예를 들어, 학습자가 자신이 공부할 단어를 선택하는 순간에 해당 단어에 대한 부가정보를 수집하여 제공한다거나, 학습자가 특정 문장을 쓰거나 읽을 때에 해당 문장에 대한 부가정보를 제공할 수 있도록 지원한다.

그림 #2. 클라이언트 서비스가 단어, 문장, 또는 단락을 입력으로 설정한 뒤 SEED API 의 함수를 호출하면 SEED API 의 함수는 입력된 내용에 대한 분석 결과를 출력하여 제공한다. (Document set 을 입력으로 받는 함수는 차기 버전에 포함될 예정)
SEED API v0.1 의 기능 구성과 활용
인포리언스는 SEED API 의 첫번째 버전 (ver. 0.1) 을 개발 완료하고 테스트를 하는 단계에 와 있다. 0.1 버전에는 다음과 같은 함수들이 포함되어 있는데 (추후에도 필요한 기능의 함수를 지속적으로 발굴하여 포함시킬 예정), 입력된 내용에 대해 각 함수가 출력하는 내용은 다음과 같다. (실제 함수명은 본 포스팅의 마지막 부분을 참조)
- 단어를 입력
- (F1) 입력된 단어의 난이도를 출력
- (F2) 입력된 단어와 같은 문장에서 함께 자주 나타나는 단어들을 출력
- (F3) 입력된 단어로부터 유추할 수 있는 다른 단어들을 출력
- (F4) 입력된 단어가 실제로 사용된 문장의 예시들을 출력
- (F5) 입력된 단어가 어떤 주제의 문서에서 주로 쓰이는 지에 대한 정보를 출력
- 문장을 입력
- (F6) 입력된 문장의 문법적 오류를 체크하여 출력
- (F7) 입력된 문장의 난이도를 출력
- (F8) 입력된 문장과 유사한 형태의 구조를 가진 예문들을 출력
- (F9) 입력된 문장과 유사한 난이도를 가진 예문들을 출력
- (F10) 입력된 문장이 어떤 주제의 문서에서 주로 쓰이는 지에 대한 정보를 출력
- 단락을 입력
- (F11) 입력된 단락에 포함된 문장의 개수와 난이도를 출력
- (F12) 입력된 단락과 유사한 난이도를 가진 단락들을 출력
- (F13) 입력된 단락이 어떤 주제의 문서에서 주로 쓰이는 지에 대한 정보를 출력
SEED API 의 활용방안의 예를 들자면 다음과 같다. (물론, 여기서 예로 언급한 방안들 외에도 클라이언트 서비스의 목적과 내용에 따라 다양한 활용 방안을 고안할 수 있다)
학습자가 특정 단어를 공부할 때 F1을 호출하면 해당 단어의 난이도를 파악할 수 있다. 따라서, 학습자가 지금까지 공부해 온 단어들의 묶음을 확보할 수 있다면 개별 단어의 난이도를 바탕으로 난이도의 통계를 얻을 수 있다. 또한 이 정보는 문장 또는 단락에 포함된 단어들의 난이도를 바탕으로 해당 문장이나 단락의 난이도를 추정할 때에도 사용할 수 있다. F2나 F3은 학습자가 특정 단어를 공부할 때에 그 단어와 함께 학습할 단어를 추천하는 과정에서 활용될 수 있다. F4는 학습자가 공부한 단어가 포함된 예문을 제시해 주고자 할 때 호출할 수 있다.
학습자가 영작을 하거나, 문장을 공부할 때에는 F7을 호출하여 학습자가 공부해 온 문장들의 난이도를 얻어 학습 수준을 추정할 수 있다. 또한 F8이나 F9의 출력을 활용하면 입력 문장과 비슷한 수준의 예문을 찾아 추천할 수 있다.
학습자가 독해를 공부한다고 하면, 독해 단락 전체를 입력 파라메터로 설정할 수 있다. 예를 들어, 학습자가 오답을 낸 단락들을 입력으로 하여 F11을 호출하면 학습자가 어떠한 수준의 독해 문제를 자주 틀리는 지를 파악할 수 있다. F13을 통해서는 학습자가 어떠한 주제의 독해 지문을 이해하는데 어려움을 겪는가를 파악하려고 할 때, 그리고 F12는 비슷한 수준의 단락을 반복해서 학습하도록 서비스를 구성하고자 할 때 활용할 수 있다.
F5, F10, F13은 단어, 문장, 단락을 입력 파라메터로 받을 수 있는데, 입력된 내용이 주로 어떠한 주제의 영문 컨텐츠에서 활용되는지 알려줄 수 있으므로, 특정 학습자의 학습 히스토리로부터 학습자가 어떤 주제를 익숙하게 여길 지를 추정하거나, 지금까지 공부해 오지 않은 주제의 학습 컨텐츠를 찾아내어 제공하고자 할 때 적절히 활용할 수 있다.
SEED API 를 기반으로 한 서비스 구성
영어 학습 과정은 학습자의 수준에 맞게, 또는 클라이언트 서비스가 제공하고자 하는 서비스의 방향에 맞게 개별적으로 구성되어야 한다. 다시 말해서, 중학교 1학년 교과서 수준의 영어 공부를 하는 학습자에게 학술 논문에서나 나올 법한 어휘나 문장을 제공하거나, TOEFL 수준의 독해 학습을 하고 있는 학습자에게 중학교 1학년 교과서에 실릴만한 단락을 높은 수준을 매겨서 추천하는 것은 적합하지 않을 것이다.

그림 #3. SEED API 가 동작하는 이면에는 corpus 를 기반으로 한 눈물겨운(?) 학습과정이 있다.
SEED API 는 사전에 제공된 corpus (말뭉치)에 들어있는 텍스트들의 특성을 미리 학습하고, 그 결과를 기반으로 각 함수들의 출력을 생산해 낸다. Corpus는 텍스트 분석 과정에서 기본적으로 사용해야 할 영문 표본의 역할을 수행하므로, corpus 에 포함된 텍스트들의 수준, 품질, 용량, 구조 등에 따라 SEED API 의 학습결과와 출력결과가 달라진다. 예를 들어, 수능 영어 학습 과정에 SEED API 를 활용하려면, 수능 영어의 수준과 내용, 품질에 적합한 corpus 를 기반으로 SEED API 를 학습시켜야 하며, TOEFL 학습 서비스에 SEED API 의 출력결과를 붙이려면 TOEFL 의 수준과 내용을 잘 표현하는 corpus 를 SEED API 에 제공하여 학습하도록 해야 한다.
인포리언스는 기본적인 표준 corpus 를 확보하고 있으나, 이러한 표준 corpus 가 모든 종류의 영어 학습 서비스에 적합할 것이라 생각할 수는 없으므로, 영어 학습 서비스의 목적과 타입에 맞는 corpus (Custom corpus) 를 바탕으로 학습 서비스 제공자가 SEED API 를 직접 학습시킬 수 있게 할 예정이다. 이를 위해 인포리언스는, SEED API 를 사용할 영어 학습 서비스들이 자신들의 corpus 를 직접 업로드할 수 있게 하는 기능을 포함시킬 예정이다. 이렇게 자신이 보유한 custom corpus 를 직접 활용할 수 있게 되면, 좋은 품질과 충분한 용량의 corpus 를 확보한 서비스 클라이언트들이 SEED API 를 활용하는 과정에서 더 좋은 결과를 기대할 수 있게 된다.
실제 함수명
- F1: getWordDifficulty()
- F2: getCoOccurringWords()
- F3: getContextuallySimilarWords()
- F4: getExampleSentences()
- F5: getContentTopics()
- F6: analyzeSentenceGrammar()
- F7: getSentenceDifficulty()
- F8: getSimilarStructureSentences()
- F9: getSameLevelSentences()
- F10: getContentTopics()
- F11: computeContentReadability()
- F12: getSameReadabilityContent()
- F13: getContentTopics()
핑백: 인포리언스 소식 (2017년 9월 ~ 2018년 2월) – Inforience
핑백: 인공지능을 비즈니스에 적용하려면… – 인포리언스
핑백: 기초적이지만 꽤 재미있는 word embedding 놀이 – 인포리언스